Nico's Homepage
Pre-Attentive Vision
My current research studies how pre-attentive vision can account to human driving behaviour in urban scenes. For an experienced driver, the act of driving requires little attention, allowing for extended periods of driving, while at the same time having a conversation, looking for directions or daydreaming. This is precisely because little attention is necessary that driver's inattention is such a common cause of accident.
Event detection
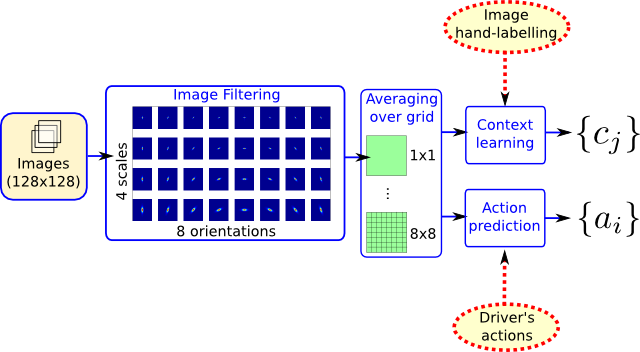
My research attempts to use visual gist (Oliva & Torralba, 2001) as an analogy to pre-attentive vision, to learn aspects of driving behaviour using data recorded from human drivers. Results at this point (see [1] for details) have showed that visual gist was apt at detecting a number of driving relevant context labels, including some very local events. Moreover, it was possible to predict up to 80% of the driver's actions on the car's pedals and steering wheel.
Autonomous navigation
Recently, we used Random Forest Regression to learn steering from a human driver and visual Gist (see [2]), both on an indoor track and on a countryside road. In both cases, the learning managed to identify the relevant parts of the scene from holistic features, without any a priori knowledge. The predicted steering behaviour was good enough for autonomous navigation around a narrow artificial track with sharp bends (90 degrees).
This work is part of the EU--project DIPLECS. Acknowledgements: Richard Bowden.
References
[1] Pugeault, N., and Bowden, R. (2010). Learning Pre-attentive Driving Behaviour from Holistic Visual Features. In Proceedings of the European Conference on Computer Vision (ECCV'2010) ECCV 2010, Part VI, LNCS 6316, pp. 154–167. (pdf)
[2] Pugeault, N., and Bowden, R. (2011). Driving me Around the Bend: Learning to Drive from Visual Gist In Proceedings of the 1st IEEE Workshop on Challenges and Opportunities in Robotic Perception, jointly with ICCV'2011. (pdf)